Summary: in this tutorial, you will learn how to use indexes with included columns to improve the speed of queries.
Introduction to SQL Server indexes with included columns
We will use the sales.customers table from the sample database for the demonstration.

The following statement creates a unique index for the email column:
CREATE UNIQUE INDEX ix_cust_email
ON sales.customers(email);
Code language: SQL (Structured Query Language) (sql)This statement finds the customer whose email is '[email protected]':
SELECT
customer_id,
email
FROM
sales.customers
WHERE
email = '[email protected]';
Code language: SQL (Structured Query Language) (sql)If you display the estimated execution plan for the above query, you will find that the query optimizer uses the index seek operation on the non-clustered index.

However, consider the following example:
SELECT
first_name,
last_name,
email
FROM
sales.customers
WHERE email = '[email protected]';Code language: SQL (Structured Query Language) (sql)Here is the execution plan:
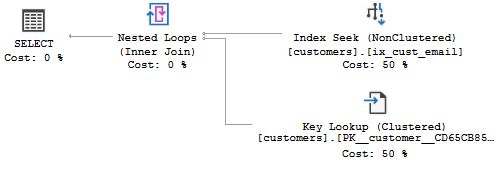
In this execution plan:
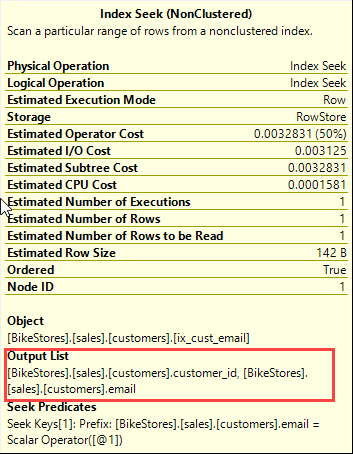
First, the query optimizer uses the index seek on the non-clustered index ix_cust_email to find the email and customer_id.
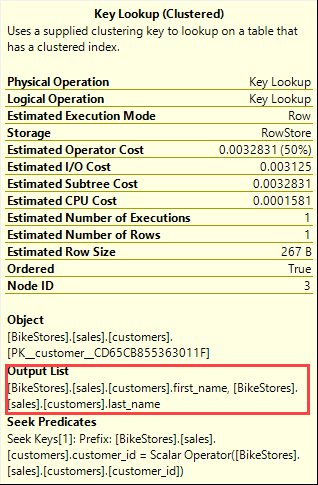
Second, the query optimizer uses the key lookup on the clustered index of the sales.customers table to find the first name and last name of the customer by customer id.
Third, for each row found in the non-clustered index, it matches with rows found in the clustered index using nested loops.
As you can see the cost for key lookup is about 50% of the query, which is quite expensive.
To help reduce this key lookup cost, SQL Server allows you to extend the functionality of a non-clustered index by including non-key columns.
By including non-key columns in non-clustered indexes, you can create nonclustered indexes that cover more queries.
Note that when an index contains all the columns referenced by a query, the index is typically referred to as covering the query.
First, drop the index ix_cust_email from the sales.customers table:
DROP INDEX ix_cust_email
ON sales.customers;
Code language: SQL (Structured Query Language) (sql)Then, create a new index ix_cust_email_inc that includes two columns first name and last name:
CREATE UNIQUE INDEX ix_cust_email_inc
ON sales.customers(email)
INCLUDE(first_name,last_name);
Code language: SQL (Structured Query Language) (sql)Now, the query optimizer will solely use the non-clustered index to return the requested data of the query:

An index with included columns can greatly improve query performance because all columns in the query are included in the index; The query optimizer can locate all columns values within the index without accessing table or clustered index resulting in fewer disk I/O operations.
The syntax for creating an index with included columns
The following illustrates the syntax for creating a non-clustered index with included columns:
CREATE [UNIQUE] INDEX index_name
ON table_name(key_column_list)
INCLUDE(included_column_list);
Code language: SQL (Structured Query Language) (sql)In this syntax:
- First, specify the name of the index after
CREATE INDEXclause. If the index is unique, you need to add theUNIQUEkeyword. - Second, specify the name of the table and a list of key column list for the index after the ON clause.
- Third, list a comma-separated list of included columns in the
INCLUDEclause.
In this tutorial, you have learned how to use SQL Server indexes with included columns to improve the query performance.