Summary: in this tutorial, you will learn how to use the SQL Server CUBE to generate multiple grouping sets.
Introduction to SQL Server CUBE
Grouping sets specify groupings of data in a single query. For example, the following query defines a single grouping set represented as (brand):
SELECT
brand,
SUM(sales)
FROM
sales.sales_summary
GROUP BY
brand;Code language: SQL (Structured Query Language) (sql)If you have not followed the GROUPING SETS tutorial, you can create the sales.sales_summary table by using the following query:
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
round(
SUM (
quantity * i.list_price * (1 - discount)
),
0
) sales INTO sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;Code language: SQL (Structured Query Language) (sql)Even though the following query does not use the GROUP BY clause, it generates an empty grouping set which is denoted as ().
SELECT
SUM(sales)
FROM
sales.sales_summary;Code language: SQL (Structured Query Language) (sql)The CUBE is a subclause of the GROUP BY clause that allows you to generate multiple grouping sets. The following illustrates the general syntax of the CUBE:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
CUBE (d1, d2, d3); Code language: SQL (Structured Query Language) (sql)In this syntax, the CUBE generates all possible grouping sets based on the dimension columns d1, d2, and d3 that you specify in the CUBE clause.
The above query returns the same result set as the following query, which uses the GROUPING SETS:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
GROUPING SETS (
(d1,d2,d3),
(d1,d2),
(d1,d3),
(d2,d3),
(d1),
(d2),
(d3),
()
);Code language: SQL (Structured Query Language) (sql)If you have N dimension columns specified in the CUBE, you will have 2N grouping sets.
It is possible to reduce the number of grouping sets by using the CUBE partially as shown in the following query:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
d1,
CUBE (d2, d3);Code language: SQL (Structured Query Language) (sql)In this case, the query generates four grouping sets because there are only two dimension columns specified in the CUBE.
SQL Server CUBE examples
The following statement uses the CUBE to generate four grouping sets:
- (brand, category)
- (brand)
- (category)
- ()
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
CUBE(brand, category);Code language: SQL (Structured Query Language) (sql)Here is the output:
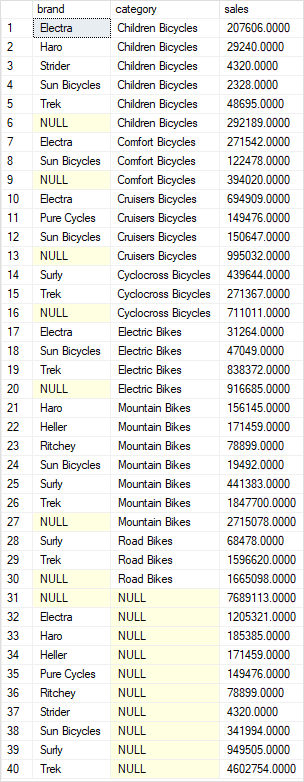
In this example, we have two dimension columns specified in the CUBE clause, therefore, we have a total of four grouping sets.
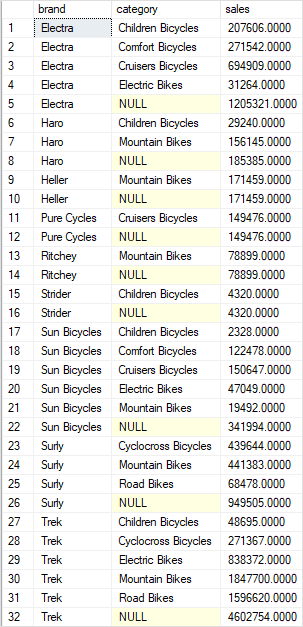
The following example illustrates how to perform a partial CUBE to reduce the number of grouping sets generated by the query:
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
CUBE(category);Code language: SQL (Structured Query Language) (sql)The following picture shows the output:
In this tutorial, you have learned how to use the SQL Server CUBE to generate multiple grouping sets.